Professional Essay Writing Service For Your Papers
Contact your writer anytime
Pay using safepayment
Prices starting from $6
Get exactly what you need
The advantages of using our essay writing service
Control the Entire Process
Affordable prices on the market
and a Money-Back Guarantee!
& AI detection reports with every order
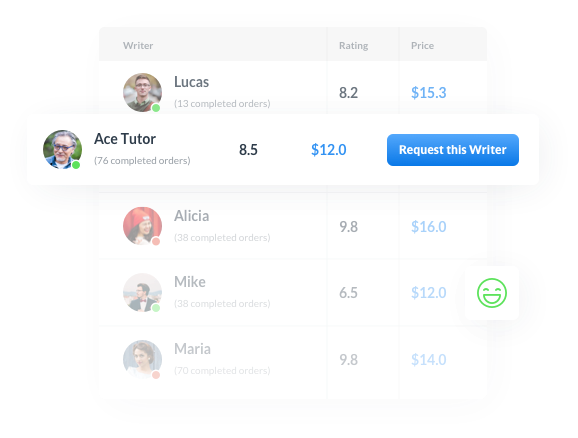
Choose Your Writer






What our customers are saying
Welcome to EssayQuest.net!
Welcome to EssayQuest.net – At our establishment, you will find the solution to all your writing requirements. Our services are unmatched, delivering custom and original high-quality writing with each order. We offer a wide array of services, and we invite you to peruse our website to acquaint yourself with the scope of our offerings, the quality of our work, and the assurances we provide.
A Professional Essay Writing Service is Only as Good as Its Writers
Once we have verified their credentials, candidates are given a topic for an original piece of writing in their field. We review their work using our strict criteria, and only then they can start to write for us. We also want people who genuinely love to write, for they are the most enthusiastic about their assignments! Writing the best college essay or paper may be drudgery for you – but it never is for your writer.
Essay Writers for Everyone
Need help with academic writing? Whether you're a high school student, an undergraduate, or a graduate student, EssayQuest.net has the right writer for you. We can assist with essays, research papers, theses, and dissertations. We also handle admissions essays, scholarship essays, resumes, CVs, and web content. Our writers are knowledgeable in various subjects and can capture your voice in the writing. They have a strong command of English and can help you achieve top scores. Despite our emphasis on quality, our prices are competitive and affordable for students.
Essay Service with More than a Smile
As the premier essay writing service in the industry, we understand the essence of exceptional customer service.. We are available 24 hours a day, 365 days a year! If it’s 2:00 a.m., and you need to place an urgent order asking us "write my essay", a live person is always there to discuss your need, to help you complete the order, and to make sure that a writer is found right away!
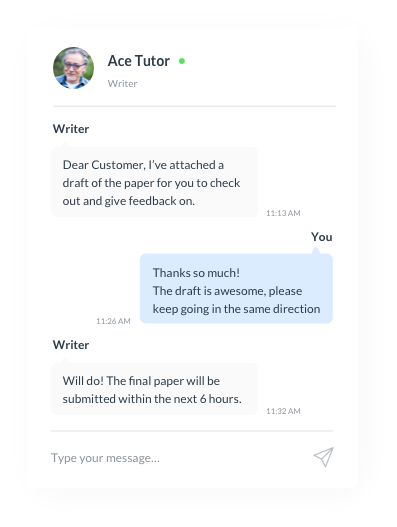
Additionally, we offer direct communication with your writer and our customer service for any inquiries or issues.
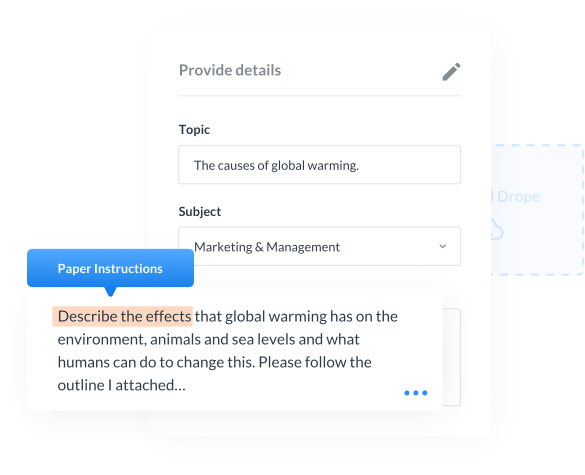
We excel in handling a wide range of writing assignments, except for essays., Including:
- Research Papers
- Dissertations
- Term Papers
- Courseworks
- Scholarship essays
- Case Studies
- Lab Reports
- Press Releases
- Book Reports
- Movie Reviews
- Annotated Bibliographies
- Multiple Choice Questions
- Editing/Proofreading
- Website content
- Product reviews
- Blogposts
- Math assignments
- CV writing
- Cover letters
- LinkedIn Bio